Marketing glossary: from SEO to AI and beyond, speaking the lingo of today’s digital marketers.
By Ethan Lazuk
Last updated:
You’re enjoying the third edition!

This third edition goes beyond SEO — my former field of focus — to include more AI and general marketing terminology.
Marketing is a specialized field where specifics, nuance, and context matter. As a result, we tend to use a lot of acronyms and jargon when speaking or writing.
This glossary can be helpful for experienced marketers as well as newcomers looking to know the lingo.
Why another glossary, though? It’s not like there’s a shortage on the web? It’s not like we don’t have AI Overviews and generative AI chatbots to give us definitions these days.
Well, this glossary will be a little different.
Personally, I love to go in depth on topics. Oftentimes, glossary definitions leave me wanting more.
These definitions will be longer, contain images, or have links to additional resources to dive in to. I’ll also add personal thoughts or experiences where relevant for richer context.
Every definition below is also 100% original.
Here are terms you can browse:
- 1-100 – 10x content | 11x content
- A – Above the fold | Activation function | AI | AI-generated content | Altavista | Attribution model | Autocomplete | Average position
- B – B2B | Backpropagation | Bard | Bing | Bing Webmaster Tools
- C – ChatGPT | Classification model | Claude AI | Click | Clickthrough rate | Content refresh | Conversion | Conversion rate | Crawler | Custom GPTs
- D – Decision boundary | Demographics | DMOZ | Domain authority | Duplicate content
- E – Ecommerce | E-E-A-T | Embedding spaces | Evergreen content | External link
- F – Favicon | Feature | Featured snippet
- G – Google Business Profile | Google Search | Google Search Console | Gradient descent | Guerrilla marketing
- H – Hashtag | Heading | Helpful content | Helpful content system | Hidden layer | HTML
- I – In-context learning | Impression | Influencer marketing | Internal link
- J – JAX | Journey mapping
- K – Keyword
- L – Link | Local SEO
- N – New Bing
- O – OpenAI | Organic search
- P – Paid Search | People-first content
- Q – Query
- R – Rankings
- S – SGE | Search intent | Search volume | SEM | Search engine optimization | SEO Twitter (X) | SERP
- T – Technical SEO
- U – Universal Search
Oh yeah, I’ve included some hidden gem definitions. See if you can spot them. 😉

If you have questions, feel free to leave a comment or contact me. I’ll be happy to help.
Now, on with the glossary!
1-100
10x content
10x content describes an approach for creating SEO content where the goal is to evaluate your competitors’ top-ranking articles for a given keyword and then make your page 10 times as good. This includes evaluating other articles’ UX, information quality, scope, and capacity for solving the reader’s problem (search intent). The term was coined by Rand Fishkin in 2015.
While the original intent of the 10x approach was to create better quality content for readers, it was later associated with practices like the skyscraper technique, which can prioritize competitor analysis and rankings over user satisfaction. In my opinion, focusing on rankings (and competitors) over users leads to search engine-first content, also known as “SEO spam.”
I don’t disagree with 10x content, but I believe a better approach for SEO content in 2024 is not to emulate competitors but instead put yourself vicariously in the user’s shoes to create more original content borne from expertise.
11x content
The term 11x content is a playful take on the next generation of 10x content, where instead of improving on competitors’ articles, the creator doesn’t take inspiration from competitors at all, instead basing the content on the user’s search intent while introducing more creativity and originality. It’s a way to create helpful, reliable, and people-first content for SEO that also stands out for doing into new creative territory, making the content hard to forget.
The inspiration for 11x content largely came after Google’s third helpful content update in September 2023. However, its viability has only grown since recent changes like Google’s hidden gems improvements or the expected aftermath of the March 2024 core update, which incorporated the helpful content system into the core ranking systems, have put more emphasis on original content.
99 Problems
A classic Jay-Z song produced by Rick Rubin, or what SEOs get when they do spammy tactics and Google Search pushes live a new ranking system or update.

The most recent that comes to mind is the March 2024 spam update and new spam policies, which include scaled content abuse, or generating pages at scale (such as with generative AI) for the express purpose of manipulating search rankings.
A
Above the fold
Above the fold refers to the visible section of a webpage that loads in the viewport before a user scrolls down.

Earlier newspapers especially were printed on large sheets of paper and folded to sell at newsstands. This meant stories above the fold were seen first by passersby, so their headlines had to grab attention!

The same applies to webpages today. (There’s a TikTok video on this topic later in the recap.)
You generally want to include your primary heading (typically an H1), so users know what content to expect.
You might also have a CTA (call-to-action) above the fold, if your visitors have clear intent to convert. Whereas uncertain visitors might want supporting text, imagery, or navigational elements or jumplinks to learn more.
In Google’s Core Web Vitals (CWV), largest contentful paint (LCP) represents the render time of the largest content element in the viewport (above the fold).

While it’s a best practice to lazy load images below the fold (waiting to load them until they’re scrolled into the viewport), above-the-fold content should load as quickly as possible. (A good LCP is under 2.5 seconds.)
Users having a satisfying above-the-fold experience is more likely to improve your metrics like dwell time, time on page, and engagement rates.
You can also measure depth of scrolling with heat maps, like in Microsoft Clarity, which shows an “average fold” dotted line.

If you monetize your website, beware of overly aggressive ads above the fold. Not only can these slow a page’s load time, but they can turn off users by diminishing the page experience.
You’l also want to be conscientious of how your title links correspond to your primary headings (H1s). If users expect one topic or angle from search results but encounter another on the page itself, they may bounce in frustration.
Overall, the better your above-the-fold experience, the more positive user interaction signals you’ll send back to search engines regarding the relevance and quality of your content, not to mention conversions.
Activation function
An activation function is a mathematical operation that takes an input and produces an output. In neural networks, it helps the model to learn nonlinear (complex) relationships between features (or individual characteristics or attributes of the input data that the model uses to make predictions) and a label (or the target output or correct answer the model is trying to predict).
Neural networks are made up of an input layer with one or more hidden layers with interconnected neurons that feed forward to an output layer. The activation function is applied to the weighted sum of the inputs to neurons in the hidden layers. Below is an example of a feed-forward neural network with a Sigmoid activation function.

The concept of nonlinear relationships is important to grasp in machine learning. Many real-world phenomena exhibit complex relationships that linear representations (such as linear regression) can’t capture. This is what makes neural networks valuable for modeling these intricate patterns and dependencies — especially deep neural networks (DNNs) for tasks like image recognition and natural language processing (NLP) — and activation functions are key here.

Common examples of activation functions include Sigmoid, tanh, and ReLU, shown on the left side below.

As a takeaway, activation functions are used within the hidden layers of neural networks and allow the models to capture intricate (nonlinear or complex) connections between input data (features) and the desired output (label).
AI
AI stands for artificial intelligence, which is the simulation of human intelligence by computers. AI machines have the ability to learn and improve without human intervention. There are different AI technologies, including natural language generation (NLG), natural language processing (NLP), neural networks, image recognition, and voice search. Within AI is also machine learning, neural networks, and deep learning.

AI is becoming a larger focus within SEO for many reasons, including that Google Search can use AI-based systems to rank web results, understand search queries, and process or understand natural language in website content.
Google’s AI systems like MUM and Gemini are also multimodal, which means they can process text, audio, video, images, and other media. One of Google’s most notable AI-based systems was the helpful content system, a machine learning-driven and automated ranking system that applied a site-wide signal (or classifier) to identify sites with low-added value content. The helpful content system is now part of Google’s core ranking systems, helping ensure users find helpful, people-first content in search results based on a variety of signals.
The first Google Search AI-system to use deep learning was RankBrain in 2015. This system helps relate words to concepts, going beyond the face-value meaning of keywords in a query to understanding the deeper nuances of search intent for more relevant results. RankBrain can contribute to the reranking of initial search results based on its understanding of the search intent of a query, which is informed by historical knowledge of which results were most relevant for the query.
Google’s use of machine-learning systems may contribute to rankings volatility in search results and, along with natural language processing, has increasingly replaced user interaction data for ensuring search quality.
AI is also used in generative AI applications powered by large language models (LLMs), such as Google Gemini, OpenAI’s ChatGPT, or Anthropic’s Claude. Google Search Labs also has Search Generative Experience (SGE), which is a generative AI chatbot above traditional search results. This is driven by a retrieval augmented generation (RAG) model, similar to Copilot with Bing (formerly Bing Chat) or Perplexity AI.
The most recent AI model is Gemini 1.5, which has potential uses for improving search quality based on understanding images and videos for multimodal results or queries, better natural language understanding of queries, or more accurate relationship extraction between entities for improved accuracy and relevance of search results.
AI-generated content
AI-generated content is website content created fully through automation using generative AI, such as ChatGPT, Gemini, Claude, or specific LLM-based content tools. This is different from AI-assisted content, which has human writing or editorial review combined with AI for brainstorming, editing, or other collaborative efforts.
Google’s guidance on AI content has been that they don’t care how content is produced as long as it’s high quality and focused on users. However, any content created to manipulate search rankings is a violation of Google’s spam policies, and this can include AI-generated content.

To what degree AI should be used for SEO content creation is a debated topic. In 2023, we saw how a website that used generative AI to rewrite their competitor’s content was manually penalized by Google for violating its spam policies. Such manual actions increased after the March 2024 spam update and new spam policies announced.
The purpose of mass-produced AI content is typically to achieve more topical coverage quickly, thus ranking for more keywords and increasing a website’s organic visibility and traffic, such as for the sake of monetization with ads or affiliate links. The sustainability of that model was always questionable, and it appears Google is cracking down on scaled content as of March 2024.
Google’s ranking systems aim to reward real human expertise or experience in content, such as through the helpful content system (now part of the core ranking systems), reviews system (now a rolling update), or hidden gems improvements.
My view has always been that generative AI should be used to create efficiencies for SEO work, but not create content directly, except for specific circumstances where unique value can still be provided. I believe AI tools like ChatGPT, Gemini, and Claude can play roles in content creation (AI-assisted content), but no AI-generated content should be published on the web without human review.
Altavista
AltaVista was a pioneering search engine created by researchers at DEC (Digital Equipment Corporation) that launched publicly on December 15th, 1995, with an initial index of around 16 million webpages.

AltaVista’s multi-threaded crawler named Scooter could perform multiple tasks simultaneously, making it much faster at crawling and indexing webpages than other crawlers of the era. 🌪️
📝 Standard transformer architectures use multi-headed attention, which focuses on different aspects of a complex problem (input sequence) simultaneously, analyzing the problem from each head’s unique perspective and expertise. Thus, parallel processing, where multiple sources aggregate information, applies in both contexts, resulting in a more efficient and holistic approach.
Combined with its powerful 64-bit Alpha processors (explained more in the dropdown), AltaVista was considerably fast. By 1996, it was handling 19 million request per day (check out the old-school source Perplexity found for that stat), making it one of the most popular search engines.
However, the rise of Google in the early 2000s gradually diminished the popularity of AltaVista (Google Trends chart in the dropdown).
During this week in 2013 (July 8th), the search engine was shut down. 🫡
You can still find AltaVista.com in search results, but it 301 redirects to Yahoo!:

It still gets a respectable number of organic hits, though, per Ahrefs:

Attribution model
Organic search is typically one touchpoint among several marketing channels that a person engages with as they move through the sales funnel. Attribution models help assign credit to those different touchpoints. Common attribution models used in GA4 include last interaction, first interaction, linear, or position based.

Analytics tools will often have a default attribution model, so it helps to analyze data from different models to draw holistic conclusions. For example, SEO tends to contribute a lot of informational content, like blog posts, that can generate brand awareness and consumer trust early on in user journeys, so it helps to assign credit for that to later purchases. On the other hand, free product listings and other shopping graph features are just one example of how organic search features can lead to direct conversions from SEO efforts, but perhaps supported by earlier social media, paid ads, or email interactions.
In a case study comparing GA4 with Shopify sales report data, I showed how the attribution model can impact the sales attributed to organic search. This is an important detail to keep in mind, especially given the complexity of today’s buyer’s journeys.
Autocomplete
Autocomplete is Google’s feature that predicts your query in the search bar using past user’s queries along with your search history and location as well as trending searches. Google estimates that autocomplete reduces typing by 25%, or an estimated 200 years of typing per day.

Autocomplete was originally called “Google Suggest” when it debuted in 2004 — a term I still hear veteran SEOs use. Autocomplete is primarily a time-saving feature, however, it does have applications for content topic research.
Today’s Google Search box is also more aligned with user’s search journeys. Google introduced People also search for (PASF) suggestions into the search box on Chrome in February 2024. Google is also increasing the amount of images in autocomplete for product or shopping results.
Other search engines also have autocomplete, like Bing (example below), Yahoo!, and DuckDuckGo.

Notably, you can see how Bing’s autocomplete incorporates AI chat prompts for its Copilot with Bing. However, AI answer engines, like Perplexity, typically don’t use autocomplete.
Average position
Average position is the topmost position for a webpage (or another link) in search results for a specific query over a designated timeframe. It is the metric SEOs use when referring to “rankings” for a keyword. Average position is usually taken from Google Search Console, but can also be reported in Bing Webmaster Tools or third-party rank-tracking software.

When SEOs describe a change in rankings, they’re referring to changes in average position for a query over a comparative timeframe, such as week over week or month over month.
While average position can be looked at for multiple pages or queries, it’s best to get as specific as possible using filters. For example, the average position reported on top of Google Search Console doesn’t tell you much, but if you filter for a specific query, device, and country, you can get more specific data.
Types of results (web, image, shopping, etc.), user locations or search histories, and other factors with SERP layouts can also impact average position. This is why t’s helpful to look at search results manually and even take screenshots for historical context.
I’d also say keyword rankings (and average position) is becoming a more obsolete metric these days, given the variety of organic search results and how dynamic they are based on Google’s machine learning ranking systems. Compared to the “10 blue links” of years ago, rankings may not capture cumulative organic visibility today. For more on this topic, I’d suggest reading the introduction to my SEO guide or Glenn Gabe’s article about alternative feeds and secondary SERPs.
B
B2B
B2B is short for “business-to-business,” which is when the target audience is other businesses or organizations, as opposed to B2C (business-to-consumer) or D2C (direct-to-consumer).
In general, B2B marketing has a longer sales cycle that involves multiple decision makers. Web searches (and SEO) can play a roll throughout various points, especially in the upper- and middle-funnel stages but also in lower-funnel product research.
The B2B conversion point for digital marketing may be for customers to request a demo or a quote, while some products or services are available for direct online sales.

I’ve created SEO strategies for different types of B2B companies, and one thing I’ve learned is that unless you have a robust website with rich data in Google Search Console, keyword research likely won’t get you too far. Instead, work with internal experts to map buyer’s journeys for various personas, identify pain points, and focus on all decision makers.
I also find it’s helpful to produce thought leadership content with a distinct voice and perspective, especially in this gen-AI era where basic glossary definitions or guides will be handled by AI Overviews, chatbots, etc.
That said, internal search features or gen-AI customer agents grounded with company documents on a B2B website could help address long-form questions most concisely.
Examples of B2B companies include technology companies (software, SaaS (software-as-a-service), or cloud services), business financial services (analytics or payroll), manufacturing (construction or industrial equipment), or marketing (CRMs, web developers, or SEO consultants). 😉
Some businesses are exclusively B2B, while others have both B2B and B2C product or service lines.
Backpropagation
Backpropagation is an algorithm in neural networks that implements gradient descent, which is an iterative process by which the system minimizes its loss function by adjusting the weights of neurons in the hidden layers. The goal is getting as close the global minimum (perfect alignment between the example and output) as possible, though neural networks commonly settle into local minima.
In short, backpropagation is a really important part of training neural networks to make accurate predictions. It calculates the gradient of the loss function (level of accuracy), which is used to update the weights of neurons to improve the network’s performance.
The reason it’s called backpropagation is because the weights are adjusted moving backward through the system from the final layer to the initial layer.
Backpropagation comes after a forward pass, where a batch of examples (the input) are processed through the neural network and the loss function is determined.
Each neuron can contribute to the overall loss in different ways, so backpropagation determines how much to increase or decrease the weights applied to neurons. This is also influenced by the activation function used. (For example, sigmoid functions can be impacted by the vanishing gradient problem (early gradients become very small, especially in deeper networks), while functions like ReLU (which we saw used in the Anthropic paper) can help mitigate that issue.)
Artem Kirsanov did a fantastic YouTube video on backpropagation recently, where he called it “the most important algorithm in machine learning.”
Here are some screenshots:





While it’s a foundational process for training neural networks, backpropagation isn’t always used.
Geoffrey Hinton’s research has been instrumental in the field of deep learning. Along with David E. Rumelhart and Ronald J. Williams, he published the 1986 paper, Learning representations by back-propagating errors, which was some of the first evidence that training a network (multi-layer perceptron) with backpropagation could train it to solve problems.
Hinton has recently proposed the forward-forward algorithm:
“As a model of how cortex learns, backpropagation remains implausible despite considerable effort to invent ways in which it could be implemented by real neurons (Lillicrap et al., 2020; Richards and Lillicrap, 2019; Guerguiev et al., 2017; Scellier and Bengio, 2017). There is no convincing evidence that cortex explicitly propagates error derivatives or stores neural activities for use in a subsequent backward pass. …
The Forward-Forward algorithm (FF) is comparable in speed to backpropagation but has the advantage that it can be used when the precise details of the forward computation are unknown. It also has the advantage that it can learn while pipelining sequential data through a neural network without ever storing the neural activities or stopping to propagate error derivatives. …
The two areas in which the forward-forward algorithm may be superior to backpropagation are as a model of learning in cortex and as a way of making use of very low-power analog hardware without resorting to reinforcement learning (Jabri and Flower, 1992).”– The Forward-Forward Algorithm: Some Preliminary Investigations (2022), Geoffrey Hinton, Google Brain
Instead of one forward pass and a backward pass (backpropagation), the FF algorithm uses two forward passes.
The first pass uses real (positive) data while the second uses generated or corrupted (negative) data. Each layer in the network has a “goodness” function, where the goal is to maximize the goodness for positive data and minimize it for negative data.
The FF algorithm is considered more biologically plausible (what our brains might do) than backpropagation.
Bing is the second largest search engine in the U.S. behind Google Search. Microsoft launched Bing in 2009 as the successor to MSN Search. Microsoft’s partnership with OpenAI, its use of generative AI and rebranding of Bing chat to Copilot, as well as tools like Bing’s Image Creator and upcoming Deep Search have brought more interest to the search engine, especially in SEO circles. However, the Bing market share is usually around 7-8% compared to 87.6% for Google as of December 2023. While SEOs primarily optimize for Google’s search results, Bing benefits SEO efforts through its transparent Webmaster Guidelines and Bing Webmaster Tools. To search on Bing, simply visit bing.com. The results and experience can be personalized based on your Microsoft account.
Bing Webmaster Tools
Bing Webmaster Tools is a free service from Microsoft that allows website owners to see a website’s performance on Bing or use other SEO tools. BWMT reports on metrics like clicks and impressions to queries or pages, as well as technical SEO issues, backlink data, or other helpful information drawn from Bing’s web crawler. Though most SEO attention is on Google’s search results, Bing Webmaster Tools has several cool features that can universally help your SEO, including an XML sitemap coverage report with a content quality flag. BWMT can also show click and impression data from web and AI chat together, though no query-level data is available yet. You can also use Webmaster Tools to set up Microsoft Clarity, a heat map, user recordings, and analytics tool I’ve used for content optimization.
ChatGPT is an AI chatbot from OpenAI that’s powered by a GPT-3 or GPT-4 (in the paid pro version) LLM. It is trained on large amounts of data gathered from scraping information from across the web and uses a type of neural network called a transformer to read text and spot patterns in words or phrases. Unlike a search engine, ChatGPT doesn’t retrieve information from the web (unless it’s using its browse with Bing feature). Rather, it makes predictions based on information it’s seen before, essentially guessing what words should come next to answer a user’s prompt. ChatGPT has a number of SEO use cases that improve efficiencies, such as schema, content inspiration, or data analysis. However, like all LLM-based tools, ChatGPT can hallucinate and make mistakes. Though this is mitigated by using live information from the web in some answers. You can access ChatGPT by visiting chat.openai.com.
Classification model
A classification model is a type of machine learning (ML) model that uses supervised learning to predict the predefined category or class to which input data belongs.

Classification models can implement classifiers, the algorithms or sets of rules or procedures the models use to assign input data to different classes or categories.
Supervised learning involves training models on labeled data, where each data point has a known class label. The goal is to learn patterns or decision boundaries. (This is different from clustering algorithms (unsupervised learning), which use unlabeled data and discover inherent groupings or structures based on similarity measures.)
A classification model might determine labels like the language of text, the type of animal in an image, or a positive or negative diagnosis for a medical condition.
There are manually coded classification models, such as rule-based classifiers that use a set of manually defined rules or criteria to determine the class label of an input.

However, many classification models are automated.
Decision trees split data based on feature values to create a tree-like structure, where decisions at each node lead to predicted class labels of leaf nodes.

Support vector machines (SVMs) find a hyperplane to separate data points of different classes.

Naive Bayes classifiers are simple and fast classification models that assume features in classes are unrelated to other features.

K-Nearest Neighbor (KNN) classify new instances of data based on the majority class of their k nearest neighbors in the training data.

Logistic regression is typically used for binary classification, modeling the probability of a data point belonging to a particular class using a logistic function.

There are also neural networks used for classification tasks.
Recurrent neural networks (RNNs) process sequential data, looping data inputs back through past layers to retain information from previous steps, and can be used for sentiment analysis of text, for example.

Convolutional neural networks (CNNs) are widely used for image and video data, detecting local patterns or features from objects or images.

Transformer-based models like BERT or RoBERTa can be fine-tuned for specific classification tasks using labeled data, like for sentiment or topic classification.

Graph neural networks (GNNs) can be used for classification when the data is structured as a graph, with nodes and edges representing entities and relationships, applying a classification layer to predict the class of individual nodes or the entire graph, like for recommendation systems or fraud detection.

In short, classification models can encompass a wide range of ML models, including neural networks, and implement classifiers (algorithms) that predict a predefined label for input data, based on supervised learning from labeled training data.
Claude AI
Claude AI is an AI assistant from Anthropic that uses a conversational interface and and transformer-based neural network architecture to perform tasks like content generation, coding, and data analysis using the Claude 2.1 LLM. For SEO purposes, Claude is often applied to content-related tasks, given its more natural style of prose. However, while Claude can read multiple documents uploaded at once, it can’t access the internet like ChatGPT or Bard. A free version of Claude is available at claude.ai.
Click
When SEOs talk about organic traffic from Google, they’re referring to clicks. A click is a metric in Google Search Console (or Bing Webmaster Tools) that happens when a user clicks on a link in a search engine results page (SERP) that takes them to a website or another property. Clicking on a link that keeps the user in the SERP (like a query refinement) doesn’t count as a click to a web property. Google Search Console reports clicks in Performance report charts and tables. There can be discrepancies between them. For example, anonymized queries may not appear in tables, but the clicks will be reported in the charts. Clicks in GSC may also not align with organic search sessions in GA4 (Google Analytics), as these tools use different tracking methods. Clicks are more helpful for understanding your site’s performance on Google Search, whereas GA4 metrics apply more to user engagement on the site itself. You can also view GSC click data in GA4 for a more complete picture.
Clickthrough rate
Click through rate (CTR) is a ratio of the number of clicks divided by the number of impressions for digital content:
CTR = clicks / impressions
In the context of SEO reporting, CTR measures how often organic search results or features get clicked in Google Search, Bing, or another search engine based on how often they appear.
You can review your site’s CTR data in Google Search Console:

I recommend viewing CTR with filters applied (when applicable) for:
- Date
- Country
- Device
- Page
- Search appearance
- Query
You generally want to understand the CTR of a given page (URL) for a specific keyword (query) with a given audience (country and device) during a time period (Date) for a type of search result (Search appearance).
You can also look at groups of related queries or pages, or otherwise consolidate the data in a way that makes sense. What you don’t want to do is look at CTR too broadly, like site-wide.
The reason is you’re looking for opportunities for improvement or indications of successful tactics, and context matters. How your organic result appears for one user (US on mobile) might be different than for another user (Canada on desktop).
If you have a low CTR for a high-impression query, that might imply a page’s title link, snippet, or thumbnail image isn’t as optimized or appealing to users as it could be. Of course, these elements are largely automated by Google these days.
Other causes of low CTR could be when a page isn’t a good match for a user’s search intent, or the user is finding better alternatives in the SERP, like maybe from an AI Overview or featured snippet, other image, video, social, or shopping results, or a more popular brand.
There are many variables behind CTR data, so improvement strategies should depend on researching and understanding the context.
When I work with clients, improving the CTR of branded queries or high-value non-branded queries is often an early goal in a strategy.
This can involve adjusting on-page elements to influence title links, snippets, featured images, or rich results from structured data (like prices or review stars for products).
That said, it’s helpful to manually search for a query on different devices and with different profiles or settings (like for location) to get a more holistic picture.
For example, look at how the desktop and mobile presentations of these SERPs could impact the CTR to my post about helpful content.
Here it is above the fold and people also ask questions on desktop:

While on mobile, it’s below the fold and PAA:

CTR can apply in other contexts of organic search, as well, like in Google Discover, people also view, or shopping results.
As for generative AI search experiences, the CTR of citations for organic web results in chatbots, assistants, or summaries, like Microsoft Copilot or Google’s AI Overviews, will be quite different compared to normal web results because it’s a wholly different context.
Fabrice Canel of Bing has talked about the “perfect click,” for example, or qualified clicks that happen when a user goes through much of their search journey in an AI chatbot before finding a highly satisfactory result.
Google’s AI Overviews offer fewer links than normal search results, typically, which can heighten the CTR from them (similar to other SERP features, like sitelinks or knowledge panels). Sundar Pichai of Google has also said AI Overviews produce higher rates of clicks. Hopefully, we’ll get data in GSC soon to verify CTR, clicks, and other AIO metrics. 😉
As a takeaway, improving the CTR of your important pages ranking for valuable queries in search results or appearing in other organic contexts can be a key part of a holistic SEO strategy.
Content refresh
A content refresh is when existing website content gets improved to enhance its value for organic search users. Typically, a refresh involves updating the content’s information or making the page more relevant, helpful, or easy to navigate. In addition to the benefits of fresher content for users, content freshness also can be a ranking factor for Google, but only for certain queries. Query deserves freshness (QDF) is an aspect of Google’s ranking systems that identifies when users are looking for up-to-date information on a topic. A separate freshness update applies to trending or recurring events, reviews, or best-of lists, where publish dates matter for data accuracy. However, content shouldn’t be refreshed just for the sake of it. Rather, content refreshes should only happen if the updates will improve the relevance, quality, or helpfulness of the content. It’s also important to use accurate publish or last-updated dates, as faking these can be a sign of unhelpful or search engine-first content.
Conversion
While keyword rankings and clicks get a lot of attention, the broader goal of SEO efforts is to support business goals, usually by assisting with conversions. A conversion is the end of a user’s journey on a website, where they take a meaningful action like a product or service purchase, request a quote or contact form submission, or newsletter signup. To report on conversions, SEOs can use tools like GA4 or Shopify marketing reports. Different attribution models can also help relate the contributions of SEO to broader user journeys through sales funnels.
Conversion rate
As SEOs, we not only want visitors to find and click on our organic search results, but we also want those visitors to be qualified, or members of the website’s target audience. One way to measure this is with conversion rate. Conversion rate is the number of conversions taken by a group of website visitors, either total or a certain segment (like users of a certain demographic or marketing channel) represented by a percentage. Conversion rate optimization (CRO) is a digital marketing discipline that overlaps with SEO in many ways and attempts to design a website to maximize conversions. A low conversion rate doesn’t necessarily imply a website is reaching the wrong audience, either. It could be that a large part of the audience is upper funnel (early in the sales funnel) and not ready to convert, or maybe the product has a long sales cycle that requires multiple touchpoints. Engagement rate in GA4 can be another way to gauge the satisfaction and quality of an audience, combined with analyzing the search intent and relevance of the queries reported in GSC that led users to the site.
Crawler
In order to index and rank information, search engines like Google first have to find the information. This is predominantly done using crawlers. A crawler (sometimes called a spider or bot) is a program used by search engines to visit publicly available webpages, gather data to store in the index, and follow links to discover more pages or resources. Crawlers like Googlebot can follow internal and external links. Site owners can prevent access, however, through documents like the robots.txt file or by using nofollow link attributes.
Sometimes, SEOs will talk about crawl budgets, or how many pages are crawled within a timeframe, and ensuring that search engine crawlers are allotting enough crawl resources to index a site’s most important content. Crawl rates refer to the number of times a day crawlers request to visit a website’s pages, and they’re set at an individual site level based on many factors, like the site’s speed, server capacity, or external demand. The general consensus for years has been that only very large sites need to worry about their crawl budgets. The Crawl stats report in GSC can help you spot irregularities in how Google crawls your site. Google uses mobile-first indexing and crawls all websites using a mobile crawler (Googlebot Smartphone) since October 2023.
Custom GPTs
Custom GPTs refers to custom versions of ChatGPT that use special instructions, extra resources, or other combinations of knowledge to perform specific actions. For example, there a number of SEO-related GPTs that do things like evaluate content helpfulness, generate structured data, help with learning SEO, or making sense of data for performance reporting. GPTs were initially freely created and shareable, but the GPT Store opened on January 10th, 2024, giving creators the ability to monetize their GPTs.
D
Decision boundary
A decision boundary is a separator between classes, either for binary or multi-class classification problems, in a machine learning model.
It helps the model determine which class a new data point belongs to based on its features or characteristics.

More technically, a decision boundary is called a problem space, where the output label of a classifier is ambiguous, i.e., it’s the dividing line between different predicted classes.
A classifier (algorithm) learns a decision boundary during training and then uses it to make predictions.
For example, if we trained a classifier to say whether a document was “helpful” or “unhelpful” based on labeled examples, it could then predict if a new document was helpful given where it fell relative to the decision boundary, as based on relevant attributes.
If the model learns the training data too well, overfitting can occur, where the boundary becomes highly complex and irregular, reducing its accuracy. The same can be said for underfitting.

What if data falls on the decision boundary? It depends!
The model might use random assignment, provide a confidence score, adjust itself, or use a soft margin, where it tolerates some data points being on the wrong side with the goal of a more generalizable model.
When it comes to classification algorithms, decision boundaries are a handy concept to know.
Demographics
Demographics refers to particular subsets within a population that share attributes in statistical data.
In the context of marketing, demographics are groups of people who share characteristics, like age, gender, income, or education.
They are used to identify a target audience or segments for tailored messaging and can inform buyer personas, channel selection (organic search, social, email, etc.), and content.
Specifically in digital marketing, demographics can determine targeted advertising with Google Ads or paid social, as well as organic strategies based on personalized campaigns.
In the context of SEO, demographics might influence keyword research, content creation, and even link-building (digital PR) outreach. They can also impact page experience decisions (like UX and design).
DMOZ
On June 5th, 1998, two developers for Sun Microsystems named Rich Skrenta and Bob Truel created a non-commercial and multilingual catalog of websites called the Open Directory Project (or ODP).
It’s better known as DMOZ, named for its original domain: directory.mozilla.org. Here’s a screenshot from 1999 via WayBack Machine:

The content of the catalog was maintained by a community of volunteers, and AOL owned it for most of its history, until the project ended on March 17th, 2017.
It’s obituary (sort of) was written on Search Engine Land by Danny Sullivan:
“DMOZ — The Open Directory Project that uses human editors to organize websites — is closing. It marks the end of a time when humans, rather than machines, tried to organize the web. …
DMOZ was born in June 1998 as ‘GnuHoo,’ then quickly changed to “NewHoo,” a rival to the Yahoo Directory at the time. Yahoo had faced criticism as being too powerful and too difficult for sites to be listed in.
It was soon acquired by Netscape in November 1998 and renamed the Netscape Open Directory. Later that month, AOL acquired Netscape, giving AOL control of The Open Directory.
Also born that year was Google, which was the start of the end of human curation of websites. …
DMOZ will live on in one unique way — the NOODP meta tag. This was a way for publishers to tell Google and other search engines not to describe their pages using Open Directory descriptions.”– RIP DMOZ: The Open Directory Project is closing (Danny Sullivan, SEL)
The site today is 400 bad request error.
There’s another website called DMOZTools.net that says it’s “an independently created static mirror of dmoz.org and has no other connection to that site or AOL,” but it appears to be broken.
There’s also ODP.org, which says, “As former directory editors, we were sad to see DMOZ announce their closure on short notice, so we decided to use their RDF file to preserve the work & create a static snapshot of their web directory.” It’s not HTTPS, so I won’t link to it here, but it does appear to work.
The ODP.org About page has some additional history, including DMOZ’s influence on Wikipedia:
“AOL did not state a reason for closing the directory. However the directory (like other general purpose web directories) saw declining influence and usage as user search behavior shifted away from web directories to search engines. This shift was accelerated by the shift to mobile devices, as searching on mobile devices made instant answers a far better user experience than a list of websites. Many major search services like Google & Bing offer instant answers & knowledge panels in their search results which aim to answer frequently asked questions.
While searchers are still interested in a diverse range of content, online usage behavior has concentrated on a few major portal sites like Facebook, Instagram, YouTube, Amazon, eBay, Netflix, Google, Twiter, and TikTok.
The web directory model of listing websites struggled to compete on relevancy with search engines that quickly surfaced the most relevant pages (or even the most relevant answers) from widely trusted websites.
Larry Sanger claimed DMOZ was an inspiration driving the launch of Nupedia, which led to the founding of Wikipedia. Content from Wikipedia is used widely by search engines in instant answers and knowledge graph results. Search engines pay to license the content from the Wikimedia Foundation.”– ODP.org About page
It’s an interesting history DMOZ has, born as a non-commercial and volunteer-supported project.
Authority building, which some call off-page SEO, is fundamental to a holistic SEO strategy. One way that third-party SEO tools try to quantify this idea is with domain authority (DA) scores. DA (sometimes called domain rating (DR), depending on the tool) is a score used to predict how likely a website is to rank in search results based on a proprietary blend of metrics, including the website’s backlink profile. The metric that was first developed by Moz and later used in some form by Ahrefs and Semrush. DA scores is reported on a scale of 1 to 100. Higher scores imply a greater likelihood of ranking in search results.
Studies haven’t found a strong statistical correlation between DA and Google rankings, however, as was pointed out in this article on Search Engine Land. Since DA is a domain-level score, that puts it at odds with how Google’s PageRank algorithm works at an individual webpage level. Google’s PageRank is based heavily on the value of incoming links (backlinks) to a webpage. It was formerly reported on a scale from 1 to 10, but is no longer displayed publicly. While Google can assess site-wide quality, such as with ranking systems like the helpful content system, it’s important to focus on page-level quality first (as this builds site-wide quality).
You may see DA get treated by some marketers like it’s a proxy for Google’s PageRank — especially by link sellers (a practice regarded as spam by search engines) who often advertise links from “high DA” sites. However, DA is not used or valued by Google and is not a good KPI for SEO in the opinion of Google representatives like John Mueller and many SEOs, myself included.
Some third-party SEO tools also have page authority (PA) scores, which are like DA but on an individual page level. While DA or PA can be useful for comparative analysis between sites or pages, as one of many metrics used, they should not be used as SEO KPIs. If you’re in a situation where your SEO work is being measured against DA or PA scores, please feel free to share the links in this definition to support evidence why that’s not a good use of energy.
Duplicate Content
Traditional SEO logic for content creation says to have one page per target keyword or, more recently, per entity. This is for practical reasons. Google has a site diversity ranking system, updated in 2019, which means websites usually won’t appear in the same top search results more than twice. It also has original content systems, which try to rank the original (and canonical) version of a page if multiple versions exist. That’s duplicate content, when the same content exists in two or more places, either pages on the same website or different domains.
There is a myth that search engines give a duplicate content penalty. There’s no Google penalty for duplicate content. The risk, rather, is that by creating multiple pages with the same content, Google may canonicalize and rank the version you didn’t want. For example, I once worked on a site where every blog post had a duplicate version created with weird formatting due to a CMS quirk, yet the poorer version had the canonical signals. This hurt the blog’s rankings overall until we reversed that.
Sometimes pages have different content but target the same topic, which creates a risk that only one of them will rank for the query, referred to as keyword cannibalization. I personally think these concerns are overrated, as long as the two content pieces satisfy unique search intents. (I covered an example of this in my people-first SEO article.)
The way to eliminate duplicate content issues is to delete and 410 or 404 the duplicate version (or maybe 301 redirect it if both versions received visits) or add a canonical tag to the duplicate versions pointing to the primary version. To check if duplicate content is indexed or how its canonicalized, you can use the URL inspection tool in Google Search Console.
E
Ecommerce
First off, does anybody know how to spell this word? Ecommerce, eCommerce, e-Commerce, E-commerce, well you get the point.
“Ecommerce” with no hyphen has the higher U.S. search volume per Ahrefs, likely because it’s simpler to type.

As for the definition:
Ecommerce is an abbreviation of “electronic commerce.” It refers to the buying and selling of goods (or services) over the internet.
This can be online retail shopping, auctions, and even digital downloads or B2B sales (recall Part 59’s vocab). Some brands are online only, while others have brick-and-mortar retail locations.
Popular ecommerce website platforms are Shopify, WooCommerce (WordPress), and NopCommerce, but most CMSs offer a store functionality.
Ecommerce SEO can focus on site structure, internal linking, and page experience, and increasingly, Google uses its shopping graph to show products in the SERPs. As we’ll see below, Merchant Center can also use a website’s product structured data for free listings.
Another key aspect of ecommerce marketing is working with other channels, like email, social media and UGC, and CRO.
Some of the most fun projects I’ve been apart of were for ecommerce brands. Of course, it can be a struggle bus ride if all teams aren’t rowing in one direction.
E-E-A-T
E-E-A-T (pronounced like eat) is an acronym from Google that refers to Experience, Expertise, Authoritativeness, and Trustworthiness. E-E-A-T encompasses a mix of concepts that describe what Google aspires to deliver with its search results.
E-E-A-T is not a ranking factor nor a ranking system; it’s a conceptualization of the actual (often non-disclosed) ranking factors that Google uses. E-A-T with one E for Expertise was introduced to Google’s Quality Rater Guidelines in 2014. In 2018, Google released a core ranking update known as the Medic Update (or the E-A-T Update), which influenced rankings around E-A-T factors, particularly for Your Money, Your Life (YMYL) webpages.
In 2022, Google added a preceding E for Experience. This ties into ranking systems like the reviews system (formerly product reviews) and is relevant in today’s era where the web has more AI-generated content (which lacks firsthand experience).
For helpful content (see below), not all aspects of E-E-A-T must be present, but Trust is the most important one.
Embedding spaces
Embedding spaces are multi-dimensional mathematical representations where words, phrases, or entire documents (and even websites, potentially) are mapped as points or vectors.

The position of these points (vectors) relative to each other (based on mathematical ways of measuring, like Euclidean distance, cosine similarity, dot product, etc.) reflects their semantic similarity (relationships based on deeper meaning and context).

The close proximity of vectors for a query and a document in an embedding space, for example, may suggest that document’s relevance (search intent alignment) for information retrieval (search engines).
Embedding spaces are fundamental to natural language processing (NLP), which involves enabling machines to understand and process human language. NLP is also foundational to today’s search engines like Google (semantic meaning) and LLMs.
By representing words as vectors (numbers or coordinates to signify their position in a continuous and high-dimensional embedding space), NLP models can capture nuanced relationships of meaning.
Here’s an example of different embeddings of the word “mole”:

Popular word embedding models for NLP tasks include Word2Vec and GloVe. However, the attention in transformers has enabled deep neural networks to encode more dense embeddings with richer context from surrounding words (think Google’s BERT or T5). This shift to transformer-based models has improved the quality of embeddings.
Search engines can leverage embedding spaces to better understand the search intent of queries and the relevance of documents or web pages (and likely much more, like authors or domains). This is the evolution to semantic search, beyond lexical (keyword-based) matches.
“So what’s the difference between traditional keyword-based search and vector similarity search? For many years, relational databases and full-text search engines have been the foundation of information retrieval in modern IT systems. For example, you would add tags or category keywords such as “movie”, “music”, or “actor” to each piece of content (image or text) or each entity (a product, user, IoT device, or anything really). You’d then add those records to a database, so you could perform searches with those tags or keywords.
In contrast, vector search uses vectors (where each vector is a list of numbers) for representing and searching content. The combination of the numbers defines similarity to specific topics. For example, if an image (or any content) includes 10% of “movie”, 2% of “music”, and 30% of “actor”-related content, then you could define a vector [0.1, 0.02, 0.3] to represent it. (Note: this is an overly simplified explanation of the concept; the actual vectors have much more complex vector spaces). You can find similar content by comparing the distances and similarities between vectors. This is how Google services find valuable content for a wide variety of users worldwide in milliseconds.”– Find anything blazingly fast with Google’s vector search technology, Kaz Sato & Tomoyuki Chikanaga (Google Cloud)
LLMs also use embedding spaces to generate coherent and contextually relevant responses based on user queries (prompts), or perhaps even personalize responses from user interaction data.
Here’s an example of a 2D embedding space:

But keep in mind, embedding spaces can have hundreds or even thousands of dimensions, each representing a different aspect of meaning.

For context, that image above is from 2016, pre-transformer architectures.
The high dimensionality of embedding spaces today allows them to capture complex semantic relationships.
In the realm of search, this can be resource intensive, though, involving tradeoffs. (Think multiple phases of ranking results.)
An example work flow for embedding spaces could be:
- Raw text data (unstructured, typically) is encoded (one-hot encoding).
- That input is then compressed into an embedding layer, either lower-dimensional (like Word2Vec or GloVe) or higher-dimensional (like BERT or MUM), as embedding vectors (learned through training).
- These embedding vectors then exist in an embedding space, which captures their semantic similarity.
- Search engines or LLMs then use that embedding space for NLP tasks.
Understanding the embedding space can be difficult (a challenge of “interpretability”). The GIF above shows the Embedding Projector from Google (2016). More recent techniques include ELM (embedding language model), where LLMs are used to transform abstract vectors into understandable narratives.
Evergreen Content
Evergreen content refers to content on a website that remains useful and relevant over time because the information remains “fresh.” For some searches, like news, Google uses its Query Deserves Freshness (QDF) system to surface up-to-date information.
Evergreen content is kind of the opposite, where the topic written about can be helpful for years, such as a guide or definition of a topic. SEOs like evergreen content because it’s more likely to maintain its rankings and continue to drive traffic sustainably.
That said, standards for helpful content change over time, and competitors sometimes create new and better content on the same topics, so it’s important to periodically evaluate and refresh content, even if it’s evergreen, to ensure it maintains its value and rankings.
External Link
An external link, also called an outbound link, is a hyperlink on a website that leads to another website page or resource on a different website. When SEOs talk about getting backlinks, they’re referring to external links on other websites pointing to their own site.
External links pass PageRank, and historically (we’re talking years ago), some SEOs tried to sculpt the PageRank flow by applying “nofollow” to select links. However, Google’s advice today is to give credit where credit is due, especially in journalism, and link to sources.
SEOs debate on whether adding external links to sources is a ranking factor, but Googlers like John Mueller have said it’s a great way to “provide value to your users,” and we know that Google tries to reward content that users like. So I say be transparent and link to your sources. Also, if you’re adding links for someone’s benefit, make sure to use the proper rel attributes like “sponsored” or “ugc.”
Favicon is short for “favorites icon.” It represents the small (square dimension) icon for a website (or webpage).
Favicons are most commonly seen in the browser tab, next to the page title. Other places they appear include social posts (when a link gets shared), browser history, and bookmark bars.
As SEOs, we also know favicons from search results.
However, as generative AI answers gain visibility along search journeys, favicons may become an even more important element for brand awareness and clicks (CTR) on linked citations.
Here’s an example from Perplexity:
Copilot with Bing:
And Google’s AI Overviews:
Getting search engines to show your site’s favicon can be a real pain, sometimes, as you can see with my site in the Bing example above.
Here are Google’s official recommendations for favicons, and here are Bing’s favicon instructions (unofficial, I believe).
One point to note about the two search engine’s favicon instructions is that Google says a favicon should be a multiple of 48px, but Bing says make it at least 16px and preferably 32px, but then WordPress also recommends site icons be 512px. (Correction: I originally said how this didn’t add up, but just realized they’re all multiples of 16px …)
I used a favicon plugin, and that worked for Google.
As for Bing, I created a separate .ico file with a size of 144px and put that in my site’s root folder.
I also just added this line of code with a type attribute, which someone in a Bing forum suggested:
<link rel="icon" href="/favicon.ico" type="image/x-icon">Technically, the user said to use rel=”shortcut icon” but that’s a legacy attribute; rel=”icon” is HTML5:
Someone also suggested reaching out to Bing’s webmaster support for help, so I tried that and will let you know how it works out!
Update (6/25): It worked! Thanks Bing!

Feature
Features are individual attributes (pieces of information) that a machine learning model uses to make predictions. They’re essentially the input variables fed into the model.

If we wanted to predict how weather conditions influence pass completion rates in NFL games, for example, we might have features like temperature, humidity, and air pressure and a label for completion rate. (Weather is a common example, likely because Google uses it in their docs.)
The ML model will learn the relationships between the features (weather conditions) and the label (completion rate).
Once trained, we can input new weather data (that the model hasn’t seen) and it can predict the expected completion rate for an NFL game.
The raw features we input might not be the most informative for the model, either. We might think humidity is important, but in reality, it’s wind direction, for example. This process of creating new features or transforming existing ones is called feature engineering.
When we talk specifically about neural networks and deep learning, features refer to its neurons. Each neuron in the input layer of a neural network represents a single feature from a dataset (one of our weather features, for example).
As that information flows through the hidden layers of a neural network, the neurons in each layer combine and transform the input features using an activation function. Each hidden neuron receives a weighted sum of outputs from the previous layer. This is how the network learns complex (nonlinear) relationships between the features to make predictions.

Feature snippets are excerpts of text from a webpage that show at the top of organic search results. Unlike normal search results, featured snippets put the text above the link to the webpage. Featured snippets are automatically generated by Google (now with the help of MUM) or Bing and intended to provide an answer to a searcher’s query, either in full or at least as a good starting point.
Featured snippet answers generally represent a consensus answer to a query. When an answer can have multiple qualified answers, Google may show multiple featured snippets, known as perspectives. (Not to be confused with the mobile perspectives filter). In my opinion, getting a featured snippet is one of the coolest feats in SEO, from a practitioner’s point of view anyway.
There are many types of featured snippets, like paragraphs or definitions, tables, and lists. The future of featured snippets is in question with the advent of chatbots in search like SGE, which have been described as “featured snippets on steroids” by some SEOS, but for now they live harmony.
Gemini refers to different things within the sphere of AI that SEOs should be aware of.
Gemini is an AI chatbot from Google that can fetch information from other Google services, including Search and YouTube. It was formerly known as Bard. Bard was initially powered by PaLM 2, but upgraded with Gemini Pro in December 2023. Gemini is a natively multimodal and multilingual AI model. Bard was rebranded as Gemini in February 2024.
Gemini is also integrated into Google assistant and Google Workspace products like Docs, Sheets, and Gmail.
You can use Gemini for various SEO applications, like identifying Google Business Profile categories or location page targets related to local search strategies or filtering data like People also ask questions in Google sheets. You can access Gemini at gemini.google.com. There’s also a paid version called Gemini Advanced.

Meanwhile, the introduction of Gemini 1.5 Pro is currently available as a test in Google AI Studio. I and many other SEOs gained early access in March 2024.

How the Gemini 1.5 model, which uses a Mixture-of-Experts (MoE) architecture — smaller expert neural networks versus one large neural network — and has a long-context understanding of up to 1 million tokens, may influence search quality in the future remains to be seen.
Google Business Profile
Google Business Profile, commonly abbreviated as GBP and formerly known as Google My Business (GMB), is a free profile that controls how your business appears on Google Search (particularly in local pack results for local intent queries or a local knowledge panel for branded navigational queries) as well as Google Maps.
SEOs generally optimize GBP listings as part of a holistic SEO strategy, while some local SEOs specialize in GBP visibility. (Bing Places for Business is a similar tool on Bing and can have data imported from GBP.)
Google Search
Google Search refers to the Google search engine. While Google Search can return both organic and paid results, SEOs often reference Google Search as meaning organic listings in the main search results (as opposed to images or shopping results).
Google Search is also a source in GA4, so SEOs may refer to the source/medium of Google/organic, which distinguishes Google organic search traffic from say Bing or DuckDuckGo, which would be different sources but the same medium: organic.
Google Search Console
Google Search Console, often referred to as Search Console or GSC, is a free tool from Google that reports on a website’s search traffic and performance in organic search results on Google, as well as identifies technical or indexing issues that could inhibit rankings or the user’s experience. Google Search Console originated in 2005, at the time called Google Sitemaps.
For many SEOs, GSC is their primary SEO tool and data source for reporting because it provides first-party data on organic search performance and can be used to identify ranking and traffic trends and opportunities for technical or content work. You can read more about GSC in my guide.
Gradient descent
Gradient descent is an optimization algorithm that is fundamental to machine learning — but also “older—much, much older,” as Google reminds us, with roots in calculus from centuries ago.
Gradient descent works by iteratively seeking the minimum value of a mathematical function. In machine learning, that function is a loss function (cost function), or the model’s error, as measured by the distance from the ideal output (based on training data) to the model’s actual output. 🎢

To use an analogy, think of gradient descent like a hiker in a fog. 🥾
They’re unable to see the full landscape 😶🌫️, but they can feel below their feet one step at a time which direction is up or down. 🗻
The hiker moves down toward the nearest valley (local minimum). However, their ideal destination (though perhaps impossible to reach) is the lowest point of the landscape overall (the global minimum) representing a perfectly trained model.
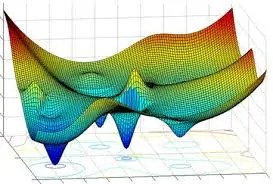
In mathematical terms, the gradient is the steepness of the hiker’s steps. It’s a vector that points in the steepest direction of a function at a particular point, either positive or negative. As its name implies, gradient descent is about finding the negative, or descending, direction.
The size of the step taken in each iteration during gradient descent is determined by a hyperparameter called the learning rate (a value set before training).

Have you heard of neural networks having parameters? They’re often described as being like little knobs that get turned to adjust a model.
Well, parameters actually refers to weights (strengths of connections between neurons) and biases (unaltered baseline activation levels for each neuron).
Backpropagation is an algorithm that neural networks use to compute the gradients needed for gradient descent. With respect to the loss function for each parameter (weight and bias), backprop gives the direction and magnitude of change needed.
That’s the turning of the knobs, so to speak.

The gradient descent algorithm then uses the gradients computed with backprop to update the model’s parameters and minimize its loss function. The larger the learning rate, the larger the updates to the weights and biases (steeper the descent).

There are different approaches to the gradient descent method.
In stochastic gradient descent (SGD), the gradient is computed using a random subset (small batch) of the data, rather than calculating the gradient over an entire dataset.
SGD can introduce noise, but it also speeds up learning (accelerating convergence, or the set of model parameters (weights and biases) that result in the minimum value of the loss function) and helps avoid getting stuck in local minima (solutions that may appear to be the lowest but aren’t the lowest overall).

Momentum can be added to gradient descent to help the algorithm navigate through areas with small but consistent gradients (think of a ball rolling down a hill, hitting a flat spot, but continuing to roll with momentum).
Momentum adds a fraction of the previous update vector to the current update (like taking the history of the past iteration into account).

To sum it up, think of gradient descent as an algorithm used to optimize machine learning models and neural networks (but it has deeper roots in calculus from centuries ago).
Gradient descent guides a model towards better performance by gradually reducing its error (loss function) through incremental adjustments to parameters (weights and biases), taking steps in a negative direction toward the best local minimum (and ideally a global minimum).
Guerrilla marketing
Guerrilla marketing is an advertising and publicity strategy that attempts to maximize exposure for a product or service using innovative, unconventional, and/or low-cost methods.

Elements of guerrilla marketing include creativity, imagination, and originality. These can compensate for a lack of a large marketing budget or abundant resources.
However, big brands do it, too.
You might’ve heard Jay-Z’s music closing out this year’s Google I/O event.
However, back in 2010, Bing teamed up with Jay-Z to create Decoded, an interactive marketing campaign that involved a scavenger hunt and a mix of art and technology.

While guerrilla marketing sounds cute, the origins come from guerrilla “warfare,” a military strategy that involves unconventional tactics. Thus, I’m proposing it’s high-time we relabel it. (For the record, I’m not anti-guerrilla. 🦍 Just not big on promulgating war motifs. 💐 ✌️)
We could describe guerrilla marketing campaigns as scrappy, thrifty, or resourceful.
However, I personally like the term “Mild West Marketing.”
This would be an homage to Banksy, the underground artist who uses unconventional placements and thought-provoking imagery for social commentary — “The Mild Mild West” was one of his first well-known pieces, a mural created in 1997 in Bristol, England. 🧸
It’d also be a play on the words “Wild West,” an era in U.S. history (post-Civil War) defined by expansion and ingenuity in less-regulated environments of the western frontier:

Where we also had the preexistence of thousands of years of indigenous culture:

(By the way, if you’re into cultural history and haven’t checked out Daniel J. Boorstin, I recommend his work, particularly “The Americans: The Democratic Experience.”)
The goals of mild west marketing (our new name for guerrilla marketing) are to grow awareness for a business or brand while also differentiating it from its competitors and connecting with potential customers in a memorable way.
Notable examples of mild west (guerrilla) marketing tactics include:
- Street marketing (street art)
- Ambient marketing (placing ads in unconventional places, creating awareness by interrupting the flow)
- Ambush marketing (taking advantage of an existing audience for another product or service; but since this one is also tied to violence, let’s relabel it “symbiotic marketing,” a term from biology where one species either benefits from another without harming or benefitting it (commensal) or both benefit (symbiotic). There’s also parasitic, a relationship we SEOs know from “site reputation abuse” spam.)
- Projections (hidden projectors on high-rise buildings)
- Experiential marketing (creating immersive experiences in real-life settings)
- Viral marketing (socially viral content — good luck planning that!) 😅
For guerrilla marketing — oops, see how hard it is to relabel something! — for mild west marketing to be effective, above all, it has to have authenticity.
Consumers are smart. They appreciate what’s clever. They see through what’s obvious.
Another necessary component, of course, is to have a distinctly recognizable brand.
H
Hashtag
Pound sign, number sign, octothorpe, hashtag, fragment identifier, tic-tac-toe thingamajig — however you call it, it’s good to know what the #️⃣ symbol is, especially if you work in marketing or SEO.
What’s cool about the “hashtag,” as we’ll call it here, is that it went from an obscure symbol on telephones and computers in the pre-internet era to having a ubiquitous presence in the realm of social media and even offline marketing.
And, oh yeah, it’s used to anchor jumplinks on webpages, too, like what you’ll see in a table of contents or from Google’s featured snippets or AI Overviews (or in this old video I made).
But let’s get one point out of the way first: hashtags won’t directly improve the visibility of your content on Instagram:

Extrapolate from that more broadly what you will (but I like to think of it as user-first optimization isn’t just for SEOs 😉).
Here’s an overview of the different ways hashtags are used, and then we’ll get into their history and modern applications, with examples:
- Pound sign: On telephone keypads, the pound sign is mostly used to signal the end of a selection or input, but it has other uses, like accessing special features (conference calling, etc.).
- Number sign: In writing, it’s an abbreviation of the word “number,” but it also has connotations in music (sharp note) and proofreading (insert a space).
- Octothorpe: In early computing, the octothorpe was used to denote comments, or non-executable lines of code, but it could also be used for preprocessor directives, like in C and C++.
- Hashtag: With the rise of social media, the hashtag became a way to group related content together, but it’s also become a means of creating brand awareness or doing trending topic research.
- Fragment identifier: These are used in webpage URLs to anchor links to a particular section of content, either on the same page or another one.
The pound sign on phones used to play a bigger role. (If you recall in Hamsterdam Part 63, we featured Americana by The Offspring (👈 jump link), where the intro says, “Please make your selection followed by the pound sign now.”)
However, modern systems use AI voice recognition technology (NLP) or touch-tone interfaces that innately understand various number combinations.
Here’s an example of the pound sign on a ’90s-era phone:

Despite what I said about hashtags for Instagram, they do serve a purpose for social media.
The hashtag was invented on Twitter in 2007 by Chris Messina. A blogger, product consultant, and open-source advocate, Chris proposed using hashtags to group related tweets together.
Twitter embraced the idea, made the hashtags clickable, and the idea spread quickly across platforms. Marketers capitalized (and abused) them.
We even see hashtags used in offline marketing:

The trick with social media hashtags is to tread lightly and use them smartly, like you would with links on a webpage.
Here’s some good advice from SgGradSister on Reddit for using hashtags on TikTok:
Don’ts:

Dos:

Personally, I’d advise using hashtags only for your audience’s benefit.
Today’s social media users are savvy, in my opinion — as many grew up using social from the jump — and spammy tactics or gimmicks will only hurt your brand’s reputation long term.
🔥 Now for the funnest (or most fun?) use of all: fragment identifiers.
I’d recommend reading Cindy Krum’s article on fraggles for MobileMoxie:

👆 See that “Source” link. That’s a jumplink to the MobileMoxie page using a feature in Chrome:

It’s the same technology Google uses in featured snippets and AI Overviews. If you look at the URL for an AIO source, for example, it adds a hashtag with extra stuff:
/hashtags-on-facebook#:~:text=3.-,Hashtags%20help…
You can add jumplinks yourself with this <a> tag for the link:
<p><a href="#part-of-the-page">Click here to jump down.</a></p>And this ID for the anchor (where users land):
<p><a id="part-of-the-page"></a>Hurray, you've landed here!</p>“But won’t that mess up my rankings in Google?!”
You’ll see fragment identifiers in your Google Search Console performance report, if they get impressions:

However, the page is still canonicalized to its primary URL (without the fragment identifier), so its ranking signals get consolidated there, but that’s just in theory.
This was said by John Mueller before (albeit in a deleted tweet):

But he also reaffirmed it on LinkedIn in June 2024:

👆 He even used some hashtags in his post. 🙌
“But won’t this mess up my internal linking and PageRank flow?!”
Google usually ignores everything after the fragment identifier (albeit, according to a deleted tweet):

When I link here to a section of a past Hamsterdam recap where John says fragment identifiers aren’t related to canonicalization, for example, Google’s systems likely see that as a normal link to the page itself.
“So does this mean the keywords I use for anchor text to sections of my page will contribute signals for that page’s overall topical meaning?!”
I guess, but doesn’t that make sense, naturally?
“Cool.”
Again, though, it’s possible — and I would almost expect — for Google’s system to be more complex, especially given how important document chunking has become for LLMs, but the above is what we know, today.
Lastly, there is something called a “hashbang,” which is #️⃣ and ❗️together. It was used in older JavaScript frameworks to indicate content changes without requiring a full page reload.
Google used to support hashbangs, but that was deprecated in 2018, likely due to slow load times and poor UX. Instead, there are more SEO-friendly JS implementations.

Here’s a jumplink to their developer doc’s explanation.
🚨 Update (7/8): Barry Schwartz reported at SER today that Google has updated (👈 jump link) its URL structure best practices doc to mention:
“Don’t use fragments to change the content of a page, as Google generally doesn’t support fragment URLs. If you’re using JavaScript to change content, use the History API instead.” (My highlight and bolding.)– URL structure best practices for Google (Google Search Central)
It then showed an example similar to: “example.com/#️⃣/tofu” — so that’s another instance to be aware of. (I’m not a JS developer, so listen to what Google says. 😅 🙌)
Heading
Heading refers to an HTML heading tag, or header tag. (HTML, described below, is the programming language used to structure webpages.) Headings are used to separate sections and subsections of content on a webpage, which is valuable in SEO for helping search engines like Google understand the content of a webpage and how it all relates together.
Headings can range from H1 to H6+ and should be hierarchical, ranking sections of text in order of importance and signifying their relationship to one another (main section, subsection, sub-subsection, etc.), keeping parity between content sections of similar weight.

The CSS of headings should also style them to match their importance (in terms of font size, etc.). For example, each webpage should have one H1 heading that describes the main topic of the page. The H1 should be the largest or most prominently styled heading on the page. Each main section of content should have an H2 heading to describe it. Any subsections within those main sections should have H3 headings. Any subsections within those subsections should have H4 headings, and so on.
SEOs can check the heading structure of a page by inspecting the rendered HTML or using an extension like Ahrefs.
Helpful Content
Helpful content is a phrase coined by Google that refers to content that is created primarily to benefit people rather than to gain search engine rankings. Helpful content often aligns with Google’s E-E-A-T criteria, such as with qualities like transparent authorship from an expert or someone with first-hand experience in a topic, but above all it’s satisfactory to an audience’s search intent.

“SEO content,” as content in an SEO strategy is sometimes called, is content that is intended to drive organic traffic from search results to a website by gaining visibility for targeted queries (keyword searches) relevant to the website’s audience. SEO content can be people-first and helpful content, or it can be search engine-first content (SEO spam).
To help surface helpful content in search results, Google introduced the helpful content system in 2022 and incorporated it into the core algorithms in 2024. This means that rather than create content intended only to rank for certain keywords, SEOs must focus on the search intent of the keywords, delivering content that can rank well because it satisfies users, not merely because it’s well-optimized for search engines.
Helpful Content System
Google’s helpful content system debuted in August 2022 and was incorporated into the core ranking systems in March of 2024. It was most known for its third update in September 2023, which caused significant visibility changes for many websites deemed to have SEO-first or overly monetized content, i.e., content that didn’t satisfy users first.

The HCS was a negative ranking system that generated a sitewide classifier indicating if a website had unhelpful content. The helpful content system thus inversely rewarded content that delivered a satisfying experience to users, i.e., meets their expectations (search intent).
Hidden layer
Nested between the input and the output layers of a neural network are its “hidden layers.” These are where the computations take place that enable the model to learn complex (nonlinear) patterns and representations from data.
Note: All images used below are from “Lecture 1: A Brief History of Geometric Deep Learning” by Michael Bronstein.
It all started with a single perceptron:

It’s a single-layer neural network with no hidden layers 👀:

Stacking multiple perceptrons together into multiple hidden layers results in a “deep neural network,” the foundation of deep learning models 🤿:

Modern deep learning architectures also use more sophisticated types of neurons than simple perceptrons, such as convolutional and recurrent neural nets, which are tailored to specific types of data.
While traditional neural networks are great at processing data in regular or grid-like structures (think images or sequences), many real-world problems involve interconnected data that’s best represented as graphs.
Graph neural networks (GNNs) apply neural network principles to these, where nodes represent entities and edges represent relationships. By aggregating information from neighboring nodes, GNNs can capture complex patterns and dependencies, such as for recommender systems, social network analysis, or drug discovery.

It’s not so much the number of layers, though. Universal Approximation Theorem posits that a single hidden layer, given a finite number of neurons, can approximate any continuous function:

Overall, deep networks tend to outperform shallow ones, given their ability to learn hierarchical representations.
Hidden layers typically use nonlinear activation functions (ReLU, sigmoid, tanh, etc.) to introduce complexity and allow the network to learn the relationships in data.
The neural network learns through backpropagation, where the weights of connections between neurons are adjusted based on the loss function (error) using gradient descent.
Gradients (degrees of adjustment to weights) can vanish or explode (get small or big) in deep networks, requiring methods like batch normalization. Other challenges include overfitting and underfitting, as well as the computational resources required for model training.
In short, hidden layers of neural networks perform feature extraction and transformation. In deep neural networks, the first hidden layer learns simple features from the input data (say the edge of an image), while deeper layers extract more complex combinations of features (like facial features or the structure of a car).

It’s this process of feature extraction that creates generalizable models that can learn from training data how to make accurate predictions on new, unseen data.
HTML
HTML is short for HyperText Markup Language, the programming language used to build the structure of webpages. While HTML builds the structure of the content, developers often apply CSS and Javascript to make webpage designs and add interactivity.
While knowing how to code in HTML isn’t a requirement for SEO, having a basic understanding of how HTML works and knowing how to apply basic elements (for example, paragraph tags <p>, heading tags <h2>, hyperlinks <a>, list items <li>, etc.) can help SEOs (as well as content writers) edit the content of webpages when creating or optimizing them.
I
In-context learning
In-context learning refers to a large language model’s ability to learn and adapt during inference (while it’s being used) by you providing the model with examples directly within the prompt of how to respond or fulfill a task. ICL differs from explicitly training a model for a task.
Google’s ML glossary says ICL is a synonym of few-shot learning, but upon further research, I believe there’s a slight nuanced difference: few-shot learning is a technique within ICL where the prompt includes a small number of examples. Using a “few” examples is likely due the constraints of context window sizes (input tokens) or for better precision.
Why is ICL necessary? Well, since LLMs are trained on large datasets, they can’t possibly learn every specific task or nuance. Few-shot learning allows a model to adapt more quickly to new situations for greater versatility.
Here’s an example prompt for ICL from Google’s ML glossary, which “contains two examples showing a large language model how to answer a query”:

Jo Kristian Bergum (who’s talk is featured in the RAG basics article I linked earlier) published a new blog post this week for Vespa.ai about “adaptive in-context learning” (there’s also an excerpt in the AI section later), where he explains:
“In-context learning can be confusing for those with a Machine Learning (ML) background, where learning involves updating model parameters, also known as fine-tuning. In ICL, the model parameters remain unchanged. Instead, labeled examples are added to the instruction prompt during inference.”– “Adaptive In-Context Learning 🤝 Vespa – part one,” Jo Bergum (Vespa.ai)
His article included example prompts, like the following one “with two examples from the training set”:

This illustrates prompt-based learning (or the technique of crafting specific prompts for few-shot learning ✍️), per Google’s ML glossary.
While ICL can make LLMs more adaptable and doesn’t require fine-tuning expertise, performance can also vary depending on the complexity of the task, quality of the examples, and capabilities of the model.
The foundation of ICL lies in the transformer architecture that powers most of today’s LLMs, specifically the mechanisms of self-attention and positional encoding.

Self-attention (red parts above) allows the model to weigh the importance of different words in the input (prompt) based on their context when generating the output (response). This enables the model to focus on the relevant parts of the examples provided during ICL.
Positional encoding helps the model understand the order of words, which is important for interpreting the structure and meaning of the provided examples.
Using its broad understanding of language patterns, syntax, and semantics (and even reasoning abilities) from the pre-training it received on massive datasets, the LLM can then recognize and generalize patterns from the ICL examples.
As Gemini Advanced also pointed out, ICL is still an active area of research, but there’s one hypothesis that says LLMs implicitly learn a wide range of tasks during pre-training, so presenting the model with examples (ICL) allows it to activate the relevant “subnetworks” within its vast parameter space to perform the specific task.
But, as mentioned, how your prompt is crafted plays an important role in guiding the model’s behavior.
Other potential drawbacks with ICL are inconsistency (especially on complex tasks or ones with limited datasets), bias (which can be inherited from the training data and manifest in ICL behavior), and a lack of explainability (or not knowing why a model predicted what it did).
Still, ICL is a promising area that has the potential to revolutionize how we interact with LLMs, especially given larger context windows that allow for more numerous or complex examples.
Impression
An impression happens when a link to a website shows up for a user in organic search results, either in the main results (such as on Google Search) or another type of result (such as Google News or Discover). The user doesn’t necessarily have to see the website to record an impression, as long as the link is on the current page of search results. (One exception is generally when the user must click to see more results.)
Impressions are reported in tools like Google Search Console and Bing Webmaster Tools. In SEO reporting, impressions can be grouped by property (one impression for all links to the same domain) or by page (one impression for each link to the domain). (See Google’s details on how they count impressions.)
While impressions indicate that a page is “ranking” for a keyword (query), more impressions aren’t necessarily better. (Rank tracking tools, for example, can inflate impressions for a keyword.) Therefore, specific goals in SEO are first to get meaningful impressions (ranking for results that are relevant to your target audience and business goals) and second to translate meaningful impressions into clicks (traffic), which results in a higher clickthrough rate (CTR).
Improved clicks and CTR generally happen by getting a webpage to rank at a high enough position for a query with a relevant and compelling title link and snippet to entice clicks.
Influencer marketing
Influencer marketing involves a collaboration between a brand and an individual who can influence the buying decisions of their following, ideally one that aligns with the brand’s target audience, based on their perceived expertise or authenticity within a niche.
Back when I was agency side, I got my first taste of influencer marketing. I found it to be a funny process.
Perhaps what’s most funny about it is how well it works can work. 🥳
I see big brands using influencers on TikTok. The beauty and health spaces are obvious ones: “Come get ready with me while I put [endorsed] shampoo in my hair.” 💆 Or rather than a super bowl ad, they’ll have someone in pajamas eating their pizza filmed on an iPhone. 🍕 That said, tech companies use influencers, too.
In my opinion, some influencer marketing happens under the table. 🫣 The FTC has guidelines for disclosing sponsored content on TikTok, for example, but all you have to do is scroll through the comments of videos to see people questioning, “Is this an ad?” 🤨
There’s also a reverse scenario, where influencers get the attention of brands and included in their promotions, like how Google featured a comedic DJ known from TikTok as the opening act at I/O this year, likely to appeal to his audience. (Content like this is what set him off. 👈)
On the flip side, social users are savvy, imo, and they can grow tired of being sold to. I’ve seen celebrity Instagram accounts lose credibility for hawking too many products: “Their feed is just them endorsing stuff.”
That said, influencers can be straight up or even have fun with it, like Cardi B often does.
The word “influencer” is kind of touchy, because we might think of people chasing clout, like by consuming laundry detergent, literally.
In reality, though, an influencer is someone with compelling expertise or experience in a knowledge domain. (So, I guess they E-E-A-T the Tide Pods. JK. 😂)
More brands today work with nano- (44%) or micro-influencers (25%) than macro ones (17%) or celebrities (13%). (Source. Also in the dropdown.)
Thanks to Discover, I also just came across this Influencity video on types of influencers that summarizes a lot of what I said but way more eloquently 😆 🙌:
Internal Link
An internal link is a hyperlink from one page to another page on the same website. It is the opposite of an external link, which points to a page on another website. Besides their utility for users, internal links play several parts in SEO strategies.
Links can pass PageRank between webpages. Partly for this reason, it’s often a best practice to internally link to prominent pages from a website’s homepage, which tends to have comparatively more PageRank. There is also a difference between navigational links, such as in a menu, and contextual links, such as links in written content.
While users follow internal links to find related content and achieve their goals, search engines use links to both discover content and understand the relationships between content. Therefore, ensuring a logical site architecture that avoids creating burdensome click depths (number of links/clicks needed to reach a page) and orphan pages (unlinked pages) through systematic internal linking is important for the user’s experience as well as SEO efforts.
The anchor text of internal links can also help influence a search engine’s understanding of the context of the destination page, not to mention help users understand where the link will take them. When creating topical clusters (such as a pillar-cluster model or hub-and-spoke model of content, where a pillar page targeting a more broad and generally higher-volume keyword links out to (and receives incoming internal links from) related content elaborating on longer-tail keywords within the same topic), using natural yet consistently themed anchor text can help establish the unique context of each piece of content in the cluster.
Link features and placement also matter. The Reasonable Surfer Model, explained well here on SEO by the Sea by the late great Bill Slawski, says that the probability a link will be clicked on matters for its evaluation by search engines.
J
JAX

Those Floridians ☀️, I tell you what …
But no, this is JAX the machine learning framework developed by Google for high-performance numerical computing and ML research. Here’s an example:

JAX provides a similar interface to and can extend the capabilities of NumPy, which stands for Numerical Python and is a fundamental scientific computing language — you might recall it from Jo Bergum’s talk on RAG basics.
What makes NumPy so important for scientific computing?
Well, basically, it offers a wide range of functions for doing math. 🧮 🙌
This can include trig, linear algebra (credit: al-jabr 😉), and Fourier transforms.
That last one, simply put, refers to converting a signal from the time domain (how it changes over time) to the frequency domain (what frequencies it’s made of). Yeah, it kind of confused me, too 😂, but I believe it “can reveal hidden patterns and insights, like identifying specific notes in a song,” per Gemini. 🎵 Sounds cool, anyway. 🤷
What’s important to takeaway is that many researchers and data scientists are already familiar with NumPy, so JAX allows them to leverage their existing knowledge.
What are the advantages of JAX, though?
Well, hardware accleration is one. NumPy is limited to CPUs, while JAX can leverage GPUs (like from Nvidia) as well as TPUs (Google’s Tensor Processing Units).
Large-scale ML tasks can require a lot of computation (and energy) and often parallelism (multiple calculations happening at once), making JAX handy for large-scale numerical calculations.
Another benefit is autograd. ML models often learn from training data using backpropagation and gradient descent. JAX’s built-in automatic differentiation makes the computation of gradients for cost functions easier (and faster). ⛷️
Other benefits include JIT (just-in-time) compilation, or compiling Python functions into optimized code on the fly. JAX also uses XLA (accelerated linear algebra), which means it’s efficient.
The one that stood out to me (because I actually recognized some of the vocabulary 😆) was function transformations for vectorization (vmap) and parallelization (pmap), which enable scaled computations and distributed computing. (Basically, machine learning can require a lot of resources, like multiple computers.)
Journey mapping
Journey mapping is the process of visualizing your audiences’ experience with your brand from start to finish, and beyond — literally, it’s everything from their initial awareness of you to them becoming a loyal customer or viewer (and evangelist/influencer on your behalf).

👉 I’ve seen people reexamining the ideas around linear customer journeys or marketing funnels, partly in light of tech and generational changes. This Brand Sauce video came to mind:
Good to roll through the comments on that video, as well. Lots of different perspectives:


Of course, we’re also familiar with Think with Google’s messy middle. 🛒 🌪️
Here are a couple of screenshots from the full PDF (which you can download in that link above):




Might have messily snuck in those middle two … 😆
And here’s an excerpt from a 2023 Think with Google article that elaborates on the messy middle in the context of behavioral science using Australian shopping data 🇦🇺:
“No two consumer journeys are exactly alike. A lot of factors come into play between the first trigger to purchase, right through to the purchase itself, and we know the path people take is rarely direct.
We call this in-between stage ‘The Messy Middle’. …
Our findings confirmed that marketers need to ensure they’re showing up with the right message, in the right place, at the right time — and that they can do this by leveraging key principles of behavioural science to provide consumers with the information and reassurance they need to make a decision.”
– The Messy Middle: How behavioural science can help you avoid a pricing race to the bottom (with my bolding).
🏈 There’s also a brand-focused sports marketer who I follow on TikTok named Jordan Rogers who used to work at Nike, and he once gave the tip to study the social sciences — psychology, sociology, anthropology (of course) — to understand human nature. 👈
Here are steps Gemini gave me (with me predicting the next tokens for explanations 😆):
🤝 1. Define your target persona.
It’s common in SEO to get audience insights from keyword data, and that’s a great start for understanding topical interests or search intents. Additionally, understanding more of the audience on a personal level, like by looking at alternative sources — and using data to avoid stereotypes — can add depth to strategies, influencing how search-facing webpages or social content gets structured (UX), worded, or visualized. 🎨
🥾 2. Identify key stages of the journey.
This gets back to the first diagram we saw earlier, where the journey starts with awareness. The steps Gemini suggested are awareness, consideration, decision, and retention or advocacy. It’s pretty standard. In my experience, marketers use different lingo depending on which resources they follow, but the core idea, as I’d explain it, is that having a little something for everyone in your target audience (and potentially beyond), through all points in time and pertinent channels (organic search, paid ads, socials, email, etc.), is never a bad idea. It is, however, a bit of work and a long-term strategy. 😂
📺 3. Map touchpoints and channels.
This involves figuring out how users find your content and what they do next. On the website side, I like to put internal links wherever I think it makes sense for the next step. (👈 Captain obvious. 🧑✈️) I never count them or worry about multiple links to the same page. It’s literally about if it can direct someone to the next step in that micro-context. Looking broader, check out the Exploration reports in GA4 or use a tool like Clarity to see how users engage with your content, and which channels are interplaying. So often that click we see in GSC wasn’t made in isolation, nor was it the first or last interaction someone had with a brand. 🗺️
Ok, wow, Gemini listed a bunch of more steps, so I’m going to just put the rest in bullet points 😅:
- 4. Gather data and insights – use GSC, GA4, and other analytics tools to gather and analyze relevant performance data indicative of user behavior.
- 5. Visualize the journey map – create a visual representation of the customer journey, complete with touchpoints, channels, emotions, pain points, and opportunities for different channels (including organic search 🙌).
- 6. Identify pain points – it never ends with ranking. What happens next counts for a lot, too. 🤗 Look for drop-off points that indicate user struggles, both micro and macro.
- 7. Develop strategies for each stage – take each stage of the journey map into account when developing an SEO or cross-channel strategy. Different stages may require different formats of content.
- 8. Implement your tactics – open that laptop (unless it has a blue screen 🙅, JK 😆) and put that strategy to use. 💪
- 9. Monitor results, iterate, and refine – follow the data and seek feedback (from real users, if possible) to adjust what’s not working or take inspiration from what is – as Rick Ross once said, “Hustle, hustlin’ hustlin’.”
📚 Further reading: “Why you need Customer Journey Mapping to Boost Engagement and Conversions” by Roberta Cinus.
A keyword is the search phrase that a user types into a search engine to find the content they’re looking for. In most contexts, SEOs refer to keywords as queries. Google Search Console, for example, provides queries reports and uses a query filter.
That said, SEOs will often refer to “keyword research” when creating lists of keywords (queries) to target or incorporate when creating or optimizing a website’s content. Some keyword research tools provide a difficulty score, which estimates how competitive a query is to rank for, typically based on the backlink profiles of the websites currently ranking for the query. Therefore, you may hear reference to high- or low-difficulty keywords.
Keywords can also be classified based on their search volumes (how often they’re searched for). Head keywords (sometimes called fat head keywords) are higher volume, more competitive, and often contain fewer words because of their general nature. Long-tail keywords are lower volume, less competitive, and usually contain several words because of their specific nature. In between these two types of keywords is sometimes called the chunky middle.
While some keyword guides distinguish head vs. long-tail keywords based on the number of terms in the query, in reality the difference relates to the level of specificity, competition, and search volume for the query. Keywords can also be broken into branded keywords (which reference a brand or its product explicitly) and non-branded keywords that reference a general topic.
Link refers to a hyperlink between two website pages. It can either be an internal link between two pages on the same website or an external link pointing from one page on a website to a page on another website. “Getting a link” typically refers to receiving a backlink, or an inbound link from another website.
Link building is the practice of proactively acquiring backlinks to a website, and the best links tend to come from relevant pages on authoritative websites and either pass PageRank or earn referral traffic.
That said, paying for backlinks or acquiring them to manipulate search rankings is considered link spam that is against Google Search’s policies and could result in algorithmic or even manual penalties on rankings.
Local SEO
Local SEO focuses on getting visibility for businesses or organizations in local search results, which are results specific to a geographic region (usually a town, city, or metro area) and tend to include traditional website results as well as Google Business Profile (or Bing Places) results as standalone profiles (local knowledge panels) or listings within map packs (local packs) and third-party listings like on industry or town directories or Yelp.
Local SEO can encompass name, address, and phone number (NAP) consistency and inclusion across directories, website content optimization for quality and location-specific keywords, as well as enhancement of Google Business Profiles along with review generation and management.
The new Bing is the Bing search engine with a chat experience powered by AI. The new Bing can give detailed replies to complex questions, summarize search results from across the web, and even write poems or generate new images.
OpenAI is the company behind ChatGPT. OpenAI has both a for-profit and non-profit wing for artificial intelligence research. Microsoft and OpenAI currently have a commercial partnership, where the former has invested $1 billion so far with plans for as much as $10 billion more in investment.
Organic Search
Organic search can have a few meanings. In the context of search engines, organic search refers to organic search results, which appear based on each webpage’s relevance to the user’s query (keyword) and how well it satisfies the criteria of the search engine’s ranking systems.
Organic search results are therefore determined algorithmically based on merit, unlike paid search results, where prominence is paid for. Alternatively, in the context of reporting, such as in Google Analytics 4, organic search refers to a medium or default channel of user traffic.
In addition to organic search results, search engines like Google also show paid search results. These results usually contain the word “Ad” or “Sponsored” and appear on the top or bottom of organic results.
Paid search uses a pay-per-click (PPC) model, where advertisers pay each time their result is clicked on by a user. Google Ads is a prominent paid search platform. There are many types of paid ads. Google Ad types, for example, can include search ads, display ads, shopping ads, video ads, and more.
As an SEO, it’s helpful to collaborate with paid ads teams to maximize results and report on traffic in context.
People-First Content
People-first content refers to content that was created foremost for people (users) instead of to earn search engine rankings. People-first content is a criterion for creating helpful content, in reference to Google’s helpful content system, and is the opposite of search engine-first content, which is created primarily to gain search engine rankings and not satisfy user’s needs.
The term “SEO content” has historically referred to content designed to rank in organic search results for relevant queries that target audience would search. People-first content can still be SEO content if it satisfies the search intent of the user.
However, when creating content based on a target query, the goal should be to create a helpful page for the user, not a page designed to rank well for the query first and satisfy the user second. Increasingly, SEO content that falls in the latter category is losing visibility anyway as Google’s ranking systems, such as the helpful content system and reviews system, get better at prioritizing E-E-A-T, information gain, and genuine examples of helpful content written for intended audiences.
Query is another name for keyword. Whereas keyword is the more general or colloquial term, query is more often used by SEO practitioners. In a formal sense of computer science, a query is a request for information or data. In SEO, query refers to the term entered into a search engine search bar. For writing, queries as SEO keywords are often denoted by [brackets].
Rankings refer to the position of a webpage for a particular query (keyword) on a search engine results page (SERP). How rankings are reported depends on the data sources and performance goals. Rankings could be done at an individual query level, such as using a rank-tracking tool or the average position of a page. fora query in Google Search Console over a timeframe.
Rankings can also refer to a page’s average position for multiple semantically relevant queries or queries of a similar search intent, or even how a cluster of topically related pages appear for the overarching topic. Since position tends to influence visibility and clickthrough rate, higher rankings are generally a goal to increase qualified traffic.
Top-10 rankings used to be imperative because that constituted page one of the SERP, however since the introduction of infinite scroll and the proliferation of SERP features, not to mention the impending introduction of generative AI in search like with SGE, rankings have become more nuanced, and the future may involve more discussions around visibility vs. rankings.
Google’s Search Generative Experience (SGE) (now AI Overviews) version of the search engine was available to Search Labs participants in the U.S. that incorporated a generative AI response for some queries in search results. SGE enables users to ask complex queries as well as related follow-up questions.
AIOs is currently being tested in different formats for different participants, and one of the hottest button issues for SEOs currently is how prominently links to websites referenced in the AI snapshot answers will be highlighted for users. (If you’re looking for updates on SGE, following SEOs on X (Twitter) who are sharing insights is one of the best ways to keep abreast of new developments.)
Search Intent (User Intent)
Search intent refers to the main goal that a user has when they search for a query on a search engine. There are many classifications for search intent (also known as user intent). The most common intent types are informational, commercial, navigational, and transactional.
Informational intent means wanting to learn or know something. Commercial intent means wanting to evaluate a product or service. Transactional intent means wanting to complete an action, namely making a purchase. While navigational intent means searching for a specific website, typically by brand name.
The user’s intent for a query determines the type of search results (and content types) that would be most useful to them. For example, a search with local intent (either implicit or explicitly expressed with modifiers like “near me”) would benefit from a local pack or map listing. Commercial intent may lead to a buyer’s guide or reviews. While transactional intent may be product, service, or category pages, along with in-SERP product listings or knowledge panels.
Sometimes the search intent of a query is more obvious (like [buy iPhone 14] is an obvious transactional query), while other times a query may have an implied intent or multiple intents depending on the individual searcher or context (like [iPhone] could be navigational, informational, transactional, or commercial).
Searches are also becoming more complex, which is partly the reason for innovations like Google’s SGE, which can allow searchers to satisfy complex intents with fewer searches using generative AI results, as opposed to returning back to the search engine from different websites across multiple searches.
As an SEO tip, if you want to rank a website for a query, first understand the dominant (and any secondary intents) by analyzing the SERPs, and then ensure your content satisfies the user intent better than what’s already out there. Monitor SERP results as well, as intent shifts can change the nature of results.
Search Volume
Search volume refers to the number of times a query is searched on a search engine, usually on a monthly average. Search volumes are based on estimates from third-party keyword research tools. Search volume (the average total searches for a query) is different from impressions (the average appearances for a query for a given website).
In the course of keyword research, keyword volume can be used to reference which phrasings of a topic or related questions are most popular. However, search volume data should be contextualized by factors like location and the variety of audiences or different intents for a query, as well as supported by audience insights and common sense for what is best for a user.
SEM
SEM is an acronym for search engine marketing, which typically refers to paid search strategies, but can also encompass SEO, intended to increase the traffic and visibility for a website in search results.
Search Engine Optimization
Search engine optimization (SEO) refers to the processes involved in optimizing a website for improved visibility in organic search results. SEO can encompass on-site and content optimization, technical aspects of the website’s functionality and indexability, as well as considerations for offsite authority signals and user experience. The term SEO can also refer to the person who does search engine optimization.
SEO Twitter (X)
SEO Twitter is the legacy name for an unofficial community of SEO professionals, enthusiasts, and related experts on the social media platform X. SEO Twitter can be a great way to learn knowledge, tactics, or stay up to date on news and developments related to Google Search and SEO in general. Alternatively, SEOs communicate and share information on platforms like LinkedIn, Mastodon, and Slack channels.
You must also exercise caution and commonsense with who you listen to about SEO advice on social media, especially after the advent of generative AI. While ChatGPT has many great uses for SEO, some people are also proposing uses that can lead to spammy results.
In my weekly SEO recaps called Hamsterdam, a good majority of the content every week is from X posts. If you’re new to using X for SEO information, I encourage you to visit there to find people to follow.
SERP
SERP is an acronym for “search engine results page.” It can contains both organic and paid search results for a query (keyword). When SEOs refer to a SERP, they usually mean the primary page of search results for a query, or the “normal” search results. Google Search has different topic bubbles to refine your results, such as images or Perspectives. These are usually defined differently, such as an “image SERP” or “Perspectives filter results.”
The contents of a SERP can vary based on factors like the query, device type (mobile vs. desktop), location, or person searching. SERP results can include normal web results, shopping results, SERP features (ex., People also view, knowledge panels, SGE snapshots, image or video carousels), related searches, and much more.
While it’s common for SEOs to report on keyword rankings using average position data for queries in Google Search Console or rank tracking changes reported in third-party tools, it’s equally important to manually check the SERPs. Given how dynamic organic search rankings and results can be, it’s important to give context for how the layout of a SERP may be impacting a result’s visibility or CTR, beyond its ranking position. I personally look at SERPs for queries on both desktop and mobile (usually using the inspect element and mobile preview developer tool) both while logged into my Google profile as well as incognito.
Technical SEO refers to SEO tactics or strategies related to a website’s indexability, site structure, speed and UX, security (HTTPS), and other advanced items. Technical SEO can also refer to a type of search marketing professional who specializes in these areas.
A technical SEO audit can be performed using many different tools, including Google tools like Google Search Console, Chrome, developer tools, or Lighthouse, or third-party tools like Screaming Frog or Sitebulb.
When performing a technical audit of a website, SEOs will often cross-reference multiple tools and prioritize the findings based on the criticality for the user experience, search performance and rankings, or business impact. For example, when analyzing Core Web Vitals, it’s important to consider if the scores are from lab data (simulated) or field data (CrUX data from eligible users).
Audit tools will also tend to put technical SEO issues into categories of severity, from errors to warnings to opportunities. While these can be useful, it’s important to consider the impact of the issue itself and the pages it impacts. Hundreds of broken links across 5 year-old press releases is likely not a big priority, whereas a missing meta description on a handful of key ecommerce category pages could be impacting CTR.
When working with an SEO services provider, it’s ok to ask questions about how they approach technical audits. I’ve personally seen instances where less-experienced people export an entire list of site audit findings from a tool, like Semrush or Ahrefs, and then give that to a client or developer to work on. Since not everything in a site audit is worth caring about, that can waste a lot of time and budget.
Additionally, resolving technical issues quickly, efficiently, and correctly can save time and prevent issues in the future. Don’t be afraid to reach out to technical SEO specialists for certain issues, especially related to issues like JavaScript and rendering.
Thank you for reading this guide and glossary! I hope you’ve enjoyed the experience and found the information helpful. 🙂
U
Universal Search
Universal Search refers to Google showing multiple types of search results beyond blue links, such as videos, images, or news. It debuted in 2007, but is now fundamental to how we think about Search — you’ll often hear SEOs referring to the “10 blue links era,” or prior to Universal Search.

Universal Search also ties in with the concept of multimodal Search, which is where users can use multiple formats, such as combining text with an image, for their query. Multimodal really entered the SEO lexicon widely with MuM in 2021 and later Gemini (a natively multimodal AI model) in 2024.
Still have questions?
If you have further questions about what you’ve read, or you’d like to learn more about a topic, please feel free to contact me.
Thanks for reading. Happy marketing! 🙂
Leave a Reply